https://jennyli6079633.blogspot.com/2019/01/anaconda-intel-realsense-python-package.html
不過其實macOS才是最需要自己編譯library的系統啊...(Linux應該也是)
因為直接pip是沒辦法安裝的
官方是說還沒開發出適用Unix平台的pypi安裝法
在這邊介紹一下如何在mac上用cmake編譯pyrealsense並使用:
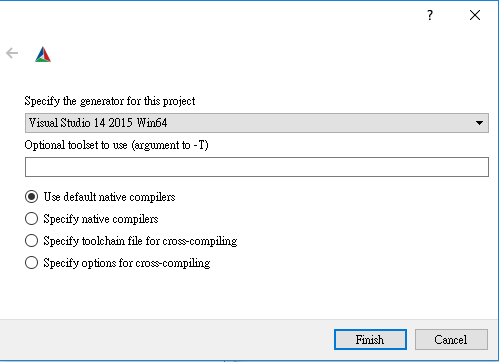
1. 下載cmake
google一下應該很多資料
連結是我參考的文章
https://blog.csdn.net/baimafujinji/article/details/78588488
照著做直到terminal輸入cmake是可以執行的就行了

直接從github clone下來最快
$git clone https://github.com/IntelRealSense/librealsense.git
3. 編譯pyrealsense2
在terminal中進入剛剛clone下來的realsense資料夾
輸入下面的指令
$mkdir build
$cd build
$cmake ../ -DBUILD_PYTHON_BINDINGS=TRUE
$make -j4
*如果environment的python版本不一樣在cmake指令後面再加上這個argument就可以了
-DPYTHON_EXECUTABLE=[full path to the exact python executable]
接著讓電腦跑(伴隨mac的悲鳴??)
都沒有error就OK了
其實跟windows系統的大同小異
不過不用像windows的cmake需要那麼多設定
4. 移動.so並建立symbolic link
跑完之後在librealsens/build/wrappers/python 資料夾中會有這些檔案

我們要建立pyrealsense2與pybackend2移到python的lib並建立的sybolic link
系統才找得到
將pybackend2.2.24.0.cpython-37m-darwin.so
與pyrealsense2.2.24.0.cpython-37m-darwin.so
複製到anaconda3/envs/(Env name)/lib/python3.7/site-packages
並在這個資料夾
然後使用下面的command
$ln -s pyrealsense2.2.24.0.cpython-37m-darwin.so pyrealsense2.so
$ln -s pybackend2.2.24.0.cpython-37m-darwin.so pybackend2.so
目前測試在anaconda的virtual env可行
如果沒有裝虛擬環境
在python的site-package加入也可以
另外還有一個方式是用make install
但是我不想直接裝在我的系統上所以我沒有使用這方法
5. 測試(可import但無法測試是否真的能跑)
進入你的虛擬環境
然後import pyrealsense2
沒有跳出找不到的錯誤就可以了

可惜我的mac沒有usb 3.0可以插所以不能測能不能真的跑起來
看有沒有人可以幫忙測的XDD
歡迎留言討論
Reference: